Aligned Variational Autoencoder で麻雀の配牌を生成する
こんにちは。taijest です。
この記事は、Sansan Advent Calendar 2021 の 7日目の記事です。
はじめに
皆さんは、在宅期間なにをして過ごしていますか? 私は、AbemaTV で放送されている麻雀リーグ「Mリーグ」にハマっています。
リーグ戦は、各チームの選手の獲得スコア合計で競い合い、一定の試合数を消化すると下位チームが脱落していくという仕組みです。 ある程度セオリーがありつつも、選手のスタイルや得点状況、チーム順位によって選択が変わってくるところがとても面白いです。
さて、麻雀の勝敗を決する大きな要素の一つとして、配牌があります。配牌とは、開局時に各選手に与えられる牌のことです。配牌は、早さ (どれだけ早くあがれそうか) や高さ (あがった時にどれだけ高い点数になりそうか) の観点から、その局の勝敗に大きく影響します。
本記事では、麻雀への理解を深めるために、この配牌の生成にチャレンジしてみます。
ナイーブな配牌生成
麻雀では、以下の 34 種類の牌を各 4 枚*1、合計 136 枚の牌を利用します。
| 大分類 | 小分類 | 例 | 種類数 |
|---|---|---|---|
| 字牌 | 風牌 | 🀁 | 4種類 |
| 三元牌 | 🀅 | 3種類 | |
| 数牌 | 萬子 | 🀉 | 9種類 |
| 筒子 | 🀟 | 9種類 | |
| 索子 | 🀔 | 9種類 |
配牌時には、これらの牌がランダムに配られるわけですから、ナイーブに配牌を生成する場合は、重複なしで抽出を行えば良いことになります。 Python では、以下のように実装ができるでしょうか。
import random n_unique_tiles = 34 n_each_tiles = 4 n_hand_tiles = 13 min_tile_code_point = 126976 max_tile_code_point = min_tile_code_point + n_unique_tiles - 1 tiles = sum( [ [chr(code_point)] * n_each_tiles for code_point in range(min_tile_code_point, max_tile_code_point + 1) ], list() ) def deal_tiles(): return str().join(random.sample(tiles, n_hand_tiles))
牌のリストからランダムに13個の要素を抽出し、文字列として返却します。
>>> deal_tiles() '🀔🀜🀒🀐🀋🀐🀛🀊🀐🀈🀞🀊🀋'
この deal_tiles 関数は実際の配牌の挙動を再現しています。ただし、配牌に関するそれ以上の情報は付与されません。
そこで、今回はさらなるチャレンジと私の勉強も兼ねて、あがれそうな役を考慮しながら配牌を生成してみます。
まずは、利用するアルゴリズムについての紹介を行います。
Aligned Variational Autoencoder
今回は、深層生成モデルの一つである、Variational Autoencoder を発展させた Aligned Variational Autoencoder を用いて配牌を生成してみます。
Variational Autoencoder *2 は、エンコーダとデコーダから構成され、reparameterization trick と呼ばれる計算技法を用いてデータを生成する確率分布を学習します。
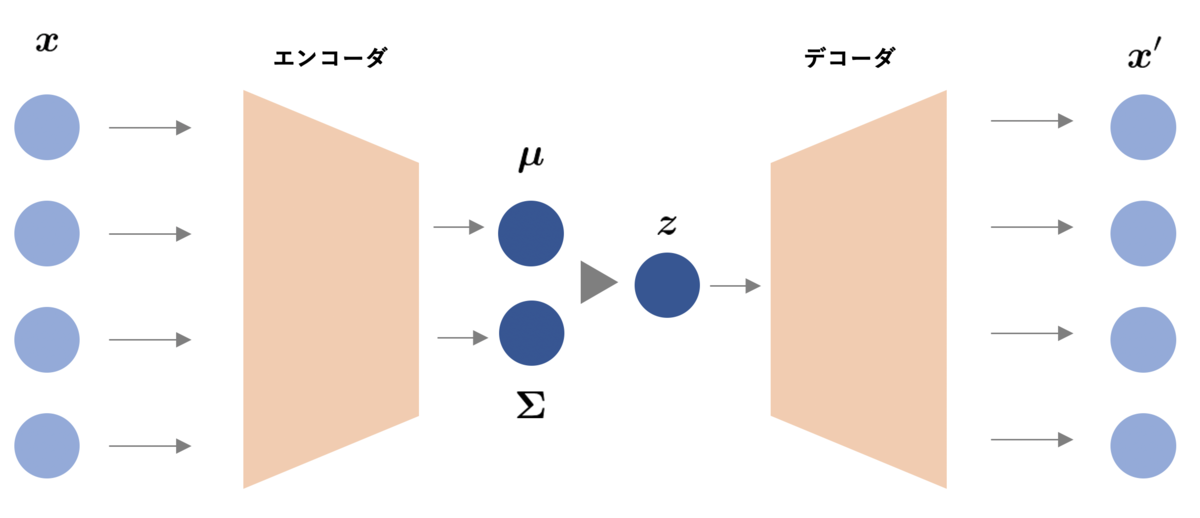
計算の詳細の説明は省きますが、入力 をエンコードした
、
を確率的に潜在変数
に変換して 入力を再現した
にデコードします。
これにより、ある確率分布からサンプリングした潜在変数 をデコードしたデータ
が得られます。この性質により、Variational Autoencoder は代表的な深層生成モデルとして様々な方向に発展した研究がなされています。
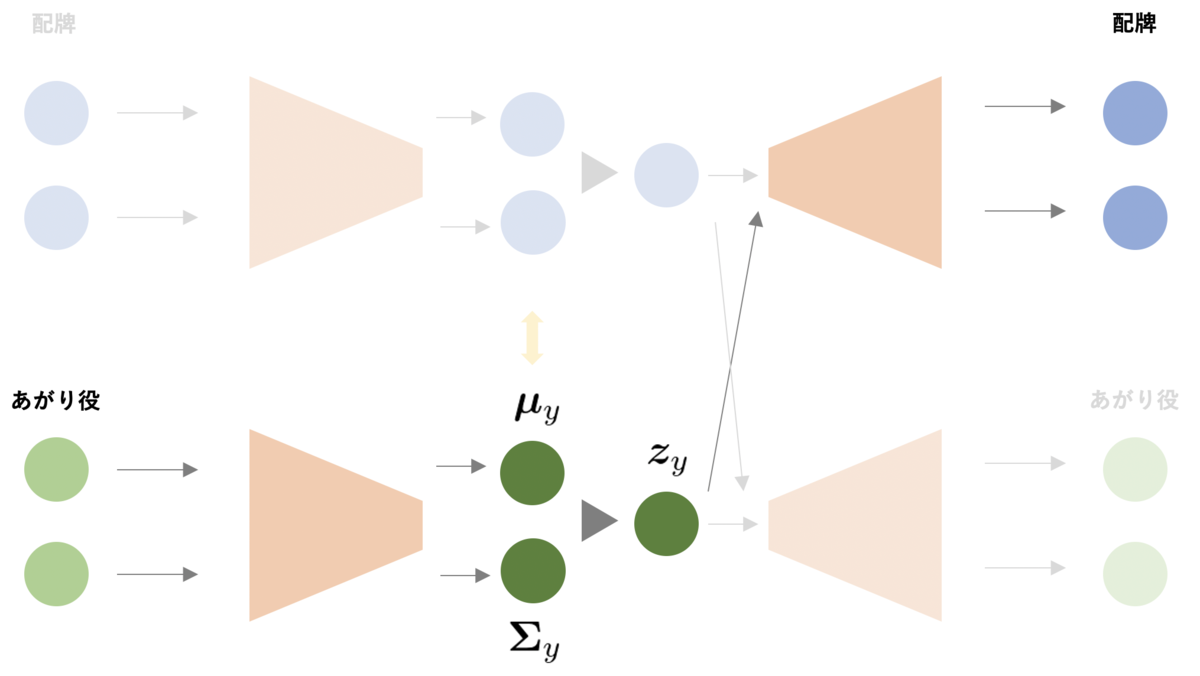
Aligned Variational Autoencoder は Variational Autoencoder を発展させたモデルの一つあり、データと付与されたラベルで共通の潜在空間を持ちます。データをエンコードした結果とラベルをエンコードした結果を潜在空間で Align するため、ラベルからもデータを生成しやすくなり、少ない学習データから画像を生成する Few-shot や Zero-shot な問題設定で有効です。

Aligned Variational Autoencoder *3 では、データとラベルにそれぞれ異なるエンコーダ、デコーダを定義し、データとラベルのエンコードされた結果が似たものとなるように学習を行います。また、データ/ラベルに対応するエンコーダから変換された潜在変数 からラベル/データをデコードできるように学習を行います。
本記事では、配牌を 、あがり役を
としてAligned Variational Autoencoder を学習します。
使用データ
対戦麻雀サイトである天鳳における、七段以上のプレイヤーによる対局データを使用します。こちらのデータは以下の記事で公開されているものを利用させていただきます。
2019 年の対局をランダムに 10,000 件選択し、あがった配牌を 136 次元 (=牌の数) のベクトルに、あがり役を 55 次元 (=役の種類数) のベクトルに変換します。麻雀牌は同一のものが 4 つずつあるため、136 次元のベクトルとして展開することは得策ではないかもしれませんが、今回はデータの扱いやすさを重視して、天鳳が提供するデータの牌の ID を参照し、136 次元のベクトルとして扱います。
Aligned Variational Autoencoder による配牌生成
生成時には以下の図のように、あがり役を入力して、エンコードした結果から変換された潜在表現から牌を生成することを考えます。
以下では、それぞれ 2回ずつモデルで生成した配牌を記載します。
パターン1: "平和, 一気通貫" を入力
'🀞🀜🀋🀠🀓🀋🀛🀙🀗🀙🀞🀐🀡' '🀅🀇🀎🀚🀜🀕🀏🀈🀕🀆🀔🀗🀎' '🀏🀓🀖🀘🀜🀊🀍🀗🀕🀅🀕🀔🀇'
一気通貫をあがりそうな配牌ということで、萬子、索子、筒子のどれかに若干偏っており、かつ順子ができそうな配牌が得られました。2番目の配牌は一気通貫に見えづらいですが、最終的にあがった役をもとに学習しているため、配牌と役が必ずしも結びつくわけではないのが難しいです。
パターン2: "大三元" を入力
'🀄🀗🀃🀜🀖🀅🀄🀠🀇🀌🀈🀝🀋' '🀐🀡🀆🀠🀇🀄🀖🀅🀖🀟🀛🀅🀐' '🀁🀐🀑🀐🀗🀀🀠🀆🀉🀏🀘🀀🀄'
分かりやすい役として、役満の大三元をあがった配牌を生成してみました。共通する特徴として三元牌である🀆🀅🀄を抱えています。3番目の配牌は他の字牌も多いので、混一色などの役をあがろうとしていたらツモが良く大三元になり得るという手でしょうか。
どちらのパターンも、なんとなくの傾向は出ているものの、しっくりこない生成例もありました。同じ役であっても、あがりの形は様々であり、その多様性をモデルが吸収するのはかなり難易度が高そうです。また、実験した後に気付いたのですが、系列として配牌を 1 枚ずつ生成した方が (牌同士の依存関係がシンプルなので) 生成は簡単そうだと思いました。気が向いたらやってみます。
おわりに
本記事では、Aligned Variational Autoencoder を実装し、あがれそうな役を入力すると麻雀の配牌を返す実験をしました。学習はうまくいったとはいえない結果でしたが、若干の傾向は掴めていそうです。
実装したことがない分野として深層生成モデルを題材にしましたが、良い勉強になりました。Aligned Variational Autoencoder 自体も研究がまだまだ進んでおり、Few-shot な問題設定以外にも活用の場はありそうです。
ここまで読んでくださりありがとうございました。良いお年を!